B2B Lead Generation Automation: Key Processes And Workflow Fundamentals
Data Capture and Segmentation for B2B Lead Automation in South Korea
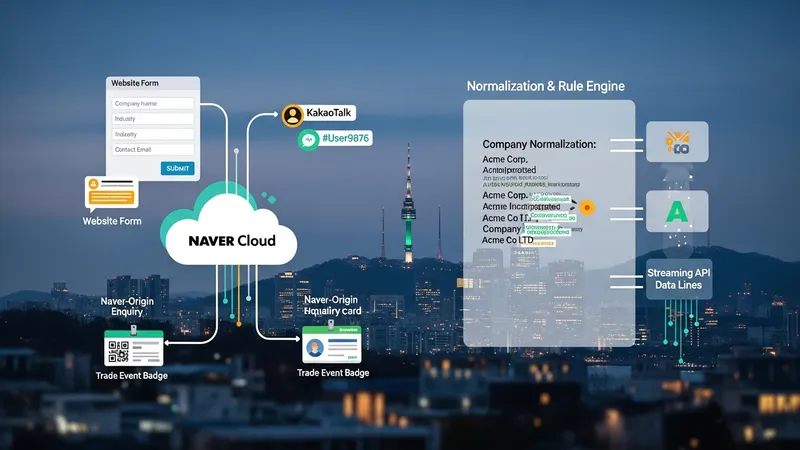
Data capture points commonly used in South Korea include website forms, KakaoTalk channel touches, Naver-originated enquiries, trade event registrations, and API feeds from partners. Each source may carry different consent or metadata requirements; for example, Kakao channels often supply a user identifier distinct from an email address. Segmentation commonly groups leads by company size, industry code, purchasing role, and digital behaviour. These segments may then determine subsequent automated paths such as educational sequences for technical buyers or pricing-oriented messaging for procurement contacts.
Practical considerations for segmentation include ensuring consistent field mappings across sources and applying basic normalization rules (company name variants, address formats) before automated rules run. Many Korean teams rely on local ETL capabilities from providers like Naver Cloud to harmonize incoming data. An important procedural element is documenting which sources feed which fields so that any downstream scoring or routing logic references reliable attributes rather than ad hoc inputs.
Consent capture and recordkeeping are often considered early in the design to support compliance with Korean privacy law. Explicit consent flags and timestamps are commonly stored alongside contact records. In addition, it may be useful to include source attribution fields that indicate the original channel and campaign for a lead; these fields typically aid later analysis of channel effectiveness without speculative attribution methods.
Segmentation rules typically start simple and refine over time. Initially, teams may use a small set of conservative segments and expand them as data volume grows and patterns emerge. This staged approach can reduce the risk of overfitting automation rules to sparse or noisy data while allowing workflows to remain interpretable for operations and sales stakeholders.