AI In Manufacturing: Understanding Applications And Industry Use Cases
AI in Manufacturing: Predictive Maintenance and Asset Monitoring
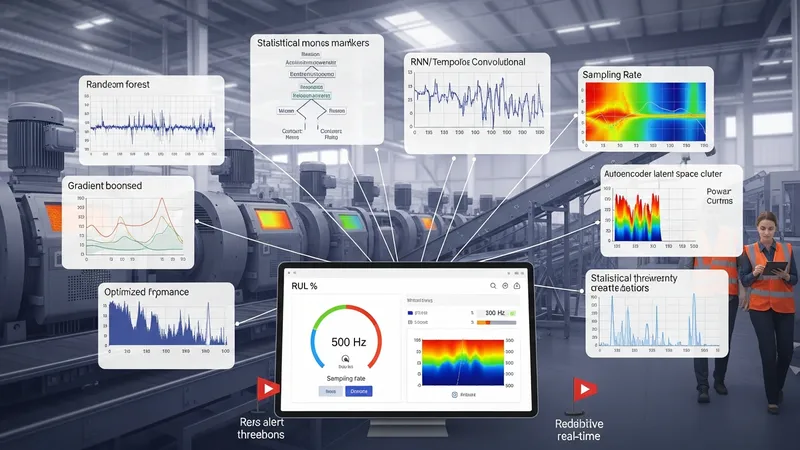
Predictive maintenance systems typically combine multiple sensor streams—vibration, acoustic, thermal, and electrical measurements—with historical maintenance and failure logs to detect precursors of equipment degradation. Time-series feature engineering such as spectral features, statistical moments, and trend indicators may feed machine learning models that estimate probabilities of failure or remaining useful life. Teams often pilot models on a subset of assets to validate signal relevance and to tune alert thresholds that balance early warning with manageable technician workload. Considerations include sensor placement, sampling rates, and procedures for collecting labeled failure events, which can be scarce in low-failure environments.
Model selection for asset monitoring often includes classical algorithms such as random forests and gradient-boosted trees, along with recurrent neural networks or temporal convolutional models when sequence dependencies are strong. Unsupervised methods like autoencoders and clustering may detect anomalies without explicit fault labels, which can be helpful where labeled data is limited. Practitioners typically validate models using holdout periods and simulated degradation scenarios, and establish monitoring to detect model drift. Instrumenting feedback loops—where maintenance outcomes are fed back to retrain models—helps maintain model relevance over time.
Operational integration often requires translating probabilistic model outputs into maintenance actions via decision rules or risk matrices. For example, a moderately elevated failure probability may trigger increased inspections, while a high probability could prompt scheduled downtime. Linking models to spare-part inventories and maintenance workforce planning is commonly necessary to realize operational improvements. Software integration with computerized maintenance management systems (CMMS) and scheduling tools helps ensure that alerts generate actionable work orders and track resolution metrics for continuous evaluation.
Practical constraints include data quality issues such as missing timestamps, inconsistent units, or sensor drift, which can degrade model performance. Insider considerations include starting with high-value asset classes, using simple baseline models for transparency, and gradually introducing more complex algorithms once data processes are stable. Teams often prepare playbooks that define who reviews alerts, how to validate predictions, and how to escalate ambiguous cases. These considerations may support reliable deployment while keeping interventions proportionate to predicted risk.