KI-basierte Trading-Tools: Funktionsweise Automatisierter Marktanalysen
Technische Komponenten und Datenquellen für automatisierte Marktanalysen
Die Effizienz KI-basierter Trading-Tools hängt stark von der Qualität und Vielfalt der genutzten Datenquellen ab. Häufig greifen die Systeme auf Börsendaten in Echtzeit, historische Kursverläufe sowie Open-Data-Angebote deutscher Börsen zu. Zudem können makroökonomische Indikatoren vom Statistischen Bundesamt oder der Bundesbank eingebunden werden, um den Kontext der Handelsentscheidungen zu erweitern.
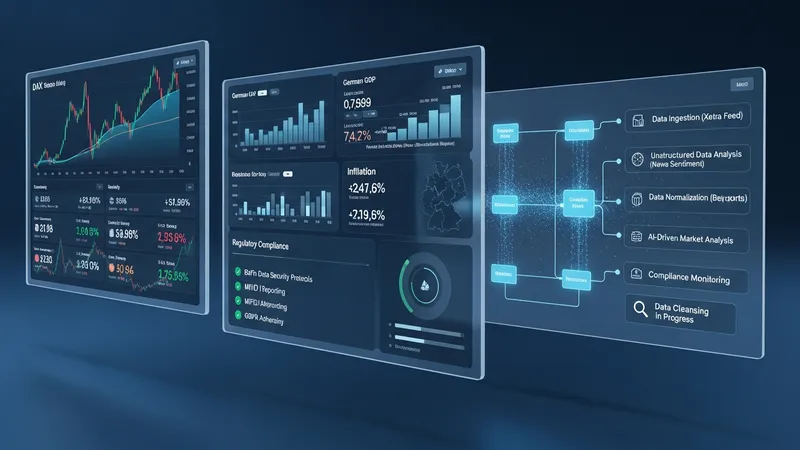
Technisch ist die Datenaggregation der erste Schritt im Analyseprozess. Hier werden strukturierte und unstrukturierte Daten gesammelt und in ein maschinenlesbares Format überführt. Dabei werden typischerweise auch Datenbereinigungs- und Normalisierungsschritte durchgeführt, um Inkonsistenzen zu reduzieren. In Deutschland können hierbei auch regulatorische Anforderungen an die Datenverarbeitung eine Rolle spielen.
Die anschließende Mustererkennung erfolgt oft mithilfe neuronaler Netze oder Entscheidungsbaumverfahren, die speziell auf die Erkennung von Kombinationen oder Abfolgen von Kursbewegungen ausgerichtet sind. Weiterhin bestehen Möglichkeiten, Prognosen auf Basis von Zeitreihenmodellen zu entwickeln. Diese Modelle können durch Machine Learning kontinuierlich verbessert werden, um auf veränderte Marktbedingungen zu reagieren.
Ein weiterer entscheidender technischer Aspekt ist die Integration mit Handelsplattformen. In Deutschland sind gängige Schnittstellen beispielsweise über FIX-Protokolle oder APIs der großen Handelsplätze etabliert. Die nahtlose Anbindung ermöglicht es, Analyseergebnisse automatisiert in Handelsorders umzusetzen, wobei die Überwachung der Systemfunktion durch Nutzer oder Compliance-Strukturen empfohlen wird.