Data Management Services: Key Functions, Capabilities, And Use Cases
Technical capabilities and integration patterns seen in Dutch implementations
Data ingestion in Netherlands projects can use a mix of batch transfers, streaming platforms, and API gateways. Streaming technologies are often chosen where near-real-time analytics are needed, while batch processes remain common for large-scale periodic loads from legacy ERP systems. Network connectivity to local exchanges in Amsterdam and direct cloud interconnects may reduce transfer times for intra-Netherlands data flows.
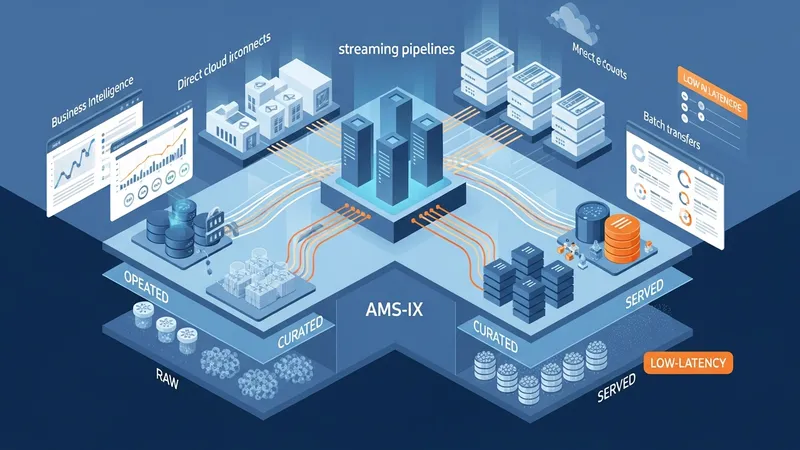
Storage architectures typically include object stores for raw data, columnar stores or warehouses for analytics, and operational databases for transactional use. Many Dutch organisations adopt a layered approach to separate raw, curated, and served data zones. This separation can simplify lifecycle policies and access controls while supporting varied consumer needs such as BI dashboards, machine-learning feature stores, or regulatory reports.
Data quality tools and practices may include profiling, validation rules, and automated alerting when thresholds are exceeded. In practice, teams in the Netherlands often integrate quality checks into pipelines so that data errors are detected early. These checks can be combined with dashboards that report quality metrics to stakeholders, helping to prioritise remediation efforts without attributing blame to specific teams.
Interoperability considerations include schema standards, canonical models, and use of APIs for cross-system data exchange. Dutch sector initiatives sometimes define common data models (for example, in healthcare or logistics) to facilitate collaboration. When common models are not available, mapping layers and transformation rules are used to translate between internal and partner schemas while preserving lineage metadata.