5G Network Management: Integrating Service Orchestration For End-to-End Automation
Service orchestration roles and mapping to network slices
Service orchestration acts as the translator between a service description and domain-level actions that realize that service. In U.S. operator environments, orchestration roles commonly include catalog management, SLA constraint enforcement, and workflow coordination across radio, transport, and core domains. When network slicing is present, the orchestration layer may assign slice parameters such as isolation, latency, and throughput to underlying resources and request resource controllers to enforce those allocations. Mapping slice intents to concrete resource reservations often requires collaboration between orchestration and resource management components, and can involve per-slice policies to meet diverse enterprise or consumer needs.
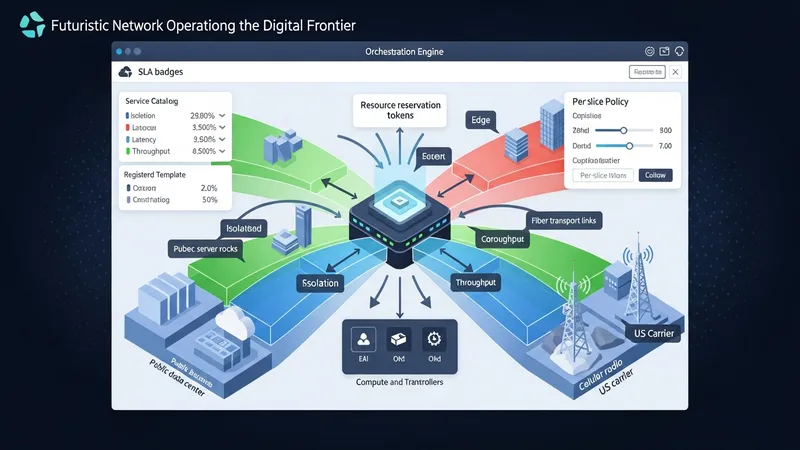
Practical mapping typically uses templates or intent models to reduce manual configuration. Registered templates in a U.S.-oriented service catalog may account for regional spectrum usage, edge site availability, and enterprise connectivity options. Orchestration systems can parameterize templates to reflect site-specific constraints and invoke resource orchestration to secure compute and transport capacity in targeted cloud or edge locations. Where service-level isolation is required, orchestration may coordinate virtual network functions and transport segmentation techniques used by U.S. carriers and infrastructure providers.
Interoperability considerations arise when slices traverse multi-vendor segments or partner domains. U.S. deployments that span carrier networks, public cloud providers, and third-party edge hosts often employ common data models or adapters to ensure consistent interpretation of slice parameters. Orchestration systems may implement translation layers to reconcile vendor-specific capabilities with standardized slice descriptors, reducing manual reconciliation during provisioning and simplifying lifecycle operations across disparate components.
Operationally, orchestration often includes validation and rollback steps that confirm resource allocations meet expected conditions before declaring a service active. In the United States, operators may run staged validations that verify radio coverage, transport latency, and compute readiness in edge sites. Automated rollbacks or remediation workflows are typically designed so that an unsuccessful provisioning attempt leaves the network in a known, safe state. This cautious approach supports predictable service activation across complex, multi-domain deployments.